Using S3 buckets for storing public websites is one of the most useful features of S3. It is a simple, cost-effective, and scalable alternative for hosting static websites or Single Page Applications. However, there are situations when creating an S3 bucket with public objects is not possible due to compliance or security reasons which can lead to the impression that you can’t use S3 for in this scenario. This is partially true, you can’t do it with S3 alone but you can add a few things and achieve the same behavior of an S3 static website hosting. Keep reading if you want to know how to do it.
TL/DR: You will need to create a CloudFront distribution that uses an S3 bucket endpoint (NOT an S3 static website endpoint) as origin, configure a CloudFront origin identity, add a custom 404 error page on the CloudFront distribution and configure a bucket policy grating GetObject and ListBucket permissions to the CloudFront identity. There is a CloudFormation template available here.
Before going through the process let me first drill down into the reasons why public websites in private S3 buckets can be tricky.
The problem with object permissions
There are two ways of managing unauthenticated access to an S3 bucket: Bucket policies and ACLs. When we configure an S3 bucket as a static website using the built-in feature we are only making the bucket behave like a traditional website so it can handle properly things such as index page, 404s, and pretty (clean || nice) URLs. Everything else remains the same, meaning that you still need a way to allow public access to the objects in your bucket. Thus, if you can’t create buckets with public objects then you also can’t use the built-in static website feature.
Why public buckets can be dangerous
I’ve witnessed cases where I found what was supposed to be private data stored as a public object in a bucket. In one case, I was using a SaaS product that was generating some reports and providing me the direct URL of the object on S3 without a pre-signed URL, which is the first indication that something is wrong. My initial hunch was to try to find the logic behind the generated report names and predict other file names so I could try to access them but they were using some sort of unique ID which would make this approach take a lot of time. However, the problem was even worse. I noticed that I could take the bucket direct URL and access it. To my surprise, listing the bucket was allowed to everyone so when I accessed the direct bucket URL a list of ALL reports stored was shown to me.
In that specific case, I not only could read any object I wanted but I could also list all available objects in there making the need to use brute force (mainly guessing) to find objects pointless. (Needless to say that I don’t use their services anymore)
That is probably AWS is making a big deal nowadays about buckets that can have public objects. You might have received some emails regarding this matter and seen things such as these:

I believe that is why you can easily block public objects to be stored on S3 buckets with a click of a button these days:

This will ensure that objects on the bucket are private and make requests for the PutObject API fail if a public-read ACL is set for example. Furthermore, it blocks policies that allow public access to unauthenticated entities which in the past was something that would only be achieved by a very complex bucket policy full of conditionals.
I personally don’t care that my static websites hosted on S3 buckets have the public-read ACL set to everybody, this is by design, however, some people freak out about it and others simply don’t know the consequences, therefore, I understand why some companies choose to create rules to block that.
The solution
There are two main problems to solve in here: How to allow public access yet remaining objects on the bucket private; Configuring website-like behavior (a.k.a set index page and a 404 page).
Let me go through the process of configuring it so I can show you the steps and I point out some of the considerations you should be aware of so this solution fits your needs.
The S3 bucket
First of all, you need to create an S3 bucket. Differently from creating a bucket to be used as a static website on its own, you don’t need to use matching names for the bucket and the public domain you want to use, so you can be creative here (or not creative at all). Also, make sure to select the “Block all public access” option:

Store your website data in this bucket. For a traditional static website, you will usually need at least 2 HTML files, one for the index page (so people hitting your naked domain address will be presented with it), and one for the not found (404) page. For this example, I will call them index.html and 404.html respectively.
Making files public
We make the files public by creating a CloudFront distribution and setting the S3 bucket as the origin. Pay attention as you should use the default S3 endpoint and NOT the S3 static website endpoint which will be something like this:
<bucket-name>.s3.amazonaws.com
Select Yes for “Restrict Bucket Access”, Create a New Identity for “Origin Access Identity”, and Yes, Update Bucket Policy for “Grant Read Permissions on Bucket” options:

Also, make sure you select the Redirect HTTP to HTTPS option to ensure that all requests are encrypted then scroll down and then set the index page name on the “Default Root Object” field:

Last, configure the rest of the distribution to your needs and click on the “Create Distribution” button to start the creation of the distribution.
What is going on
So far what we did was configure the CloudFront distribution to serve the files from the S3 bucket by leveraging a thing called Origin Access Identity. This authorizes the CloudFront service to access the private objects in the bucket using the S3 API, that way, the objects can remain private while public read access is still available through the CloudFront endpoint that will be created.
This solves the first problem plus partially solves the second problem because the index page was set int the “Default Root Object” field but we haven’t configured a 404 page, yet. To configure a 404 page, you can leverage the custom error page feature of CloudFront. To do that, open your distribution’s settings, and in the “Error Pages” tab click on “Create Custom Error Response”.
This will open a form on which you can specify the details of the error page, in our case we want to serve 404.html whenever CloudFront can’t find an object. The configuration should look like this:

Note that in this form we need to put the / before the object path (/404.html).
Note for Single Page Applications (SPAs)
When hosting SPAs the only difference would be that in the custom error page setup you would configure the distribution to return the index.html file and a 200: OK custom response code:

Filling the gaps
After that CloudFront distribution is available you will be almost set. If you try the distribution endpoint you should see your index page:

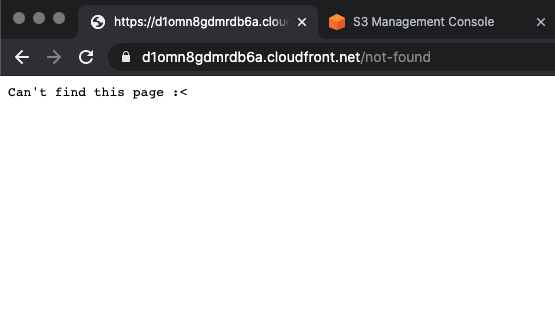
However, the custom 404 page won’t work just yet:

This happens because behind the scenes the CloudFront service calls the S3 API more specifically the ListBucket action and when we select Yes, Update Bucket Policy on the “Grant Read Permissions on Bucket” option during the distribution creation we are creating a Bucket Policy that grants only the GetObject permission not the ListBucket so we need to fix that.
To fix it go to the S3 console, select the bucket, go to the “Permissions” tab and click on “Bucket Policy”. It should look like this:
{
"Version": "2008-10-17",
"Id": "PolicyForCloudFrontPrivateContent",
"Statement": [
{
"Sid": "1",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity E1YMLZGB8K813A"
},
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::my-super-dupper-cool-bucket/*"
}
]
}
You should update the policy to add the ListBucket permission, and since it runs against the bucket, not the objects you should also add the bucket itself on the Resource section. In the end, it should look like this:
{
"Version": "2008-10-17",
"Id": "PolicyForCloudFrontPrivateContent",
"Statement": [
{
"Sid": "1",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity E1YMLZGB8K813A"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::my-super-dupper-cool-bucket/*",
"arn:aws:s3:::my-super-dupper-cool-bucket"
]
}
]
}
Now the distribution will be able to handle 404s properly:
Wrapping up
Now everything is set, and you can use the distribution endpoint as a website. Note that it will not work with static websites that use pretty URLs as CloudFront itself doesn’t know how to handle that. If you want this kind of behavior you can use the Lambda@Edge feature to process requests on your CloudFront distribution. An example can be found here. For SPAs, pretty URLs will always work (if configured in the SPA) cause they are generated via Javascript and not real HTML files.
BTW Lambda@Edge can be used to add any (within its limits) functionality at low costs to static websites. One example is configuring basic HTTP authentication for static websites (link here) which should be enough for internal documentation websites that should be kept private yet easily available to the right people.
If you want to use this approach but you are too lazy to do it I created a CloudFormation template that automates the whole setup and it is available here. The template creates the bucket, the bucket policy, the distribution, and the origin access identity. Feel free to use and share it!